Les enjeux de l’information à l’ère numérique vus par les français
Le médialab propose une nouvelle exploitation des données collectées dans le cadre de la consultation citoyenne du projet DE FACTO, menée à l’été 2022 par l'organisation Make.org. Basée sur de l’analyse linguistique, elle permet d'identifier les préoccupations des participants et les regroupements autour de certains sujets.
Dans le cadre du projet De Facto et à l'initiative du CLEMI, de Sciences Po, de l'AFP, et de XWiki SAS, l'organisation Make.org a été sollicitée pour réaliser une consultation citoyenne autour de la question “Comment permettre à chacun de mieux s'informer ?” à l’été 2022. L'objectif de cette consultation était de saisir les solutions imaginées par les français face à l'essor de la désinformation en ligne.
113 227 participants ont ainsi contribué à la consultation en formulant 2 023 propositions et en exprimant 526 858 votes (pour, contre ou neutre) sur celles-ci.
Lister 15 idées prioritaires : l’objectif de Make.org
L'équipe de Make.org a analysé les résultats de cette consultation en réalisant une analyse linguistique et statistique pour identifier les propositions ayant recueilli le plus large soutien auprès des participants.
Parmi les 2 023 propositions faites par les participants, l'équipe de Make.org en a analysé 1 723 valides au regard de sa charte de modération, puis a sélectionné 1 063 propositions pour lesquelles au moins 70% des votes étaient favorables.
Avec cet échantillon, l'équipe a fait ressortir de la consultation 15 idées prioritaires résumant les positions les plus souvent soutenues pour mieux s'informer et lutter contre la désinformation en ligne.
Liste des 15 propositions :
- Encourager une approche critique de l'information.
- Renforcer l'éducation aux médias et à l'information à l'école.
- Former à la détection des fake news et à la vérification de l'information.
- Assurer l'indépendance éditoriale des médias.
- Proposer une information plus diversifiée.
- Réguler plus efficacement les réseaux sociaux.
- Renforcer les pratiques de vérification de l'information.
- Sanctionner la diffusion de fake news.
- Sourcer et référencer autant que possible les informations publiées.
- Ne pas céder à la culture de buzz et du sensationnel.
- Lutter contre la concentration des médias.
- Exiger davantage d'expertise dans le traitement de l'information.
- Accroître la transparence sur le financement et les intérêts des médias.
- Améliorer la protection des journalistes et des lanceurs d'alerte.
- Mieux encadrer les publicités.
Identifier des thèmes fédérateurs et leurs imbrications : l'analyse du médialab
Cherchant à valoriser les données brutes de la consultation en se posant d'autres questions de recherche que celle qui a guidé l'analyse de Make.org, le médialab a, dans un premier temps, produit une analyse linguistique sur les sujets discutés parmi les 1 723 propositions valides, sans chercher à prendre en compte le sens des votes correspondants. L'objectif de cette approche était d'identifier les préoccupations des participants derrière les idées proposées, quel que soit le soutien qu'elles ont pu recevoir. Dans un deuxième temps, le médialab a réalisé une analyse de réseau centrée sur le soutien ou rejet exprimés par les mêmes participants en vue d'étudier si des regroupements de participants se formaient autour de certains sujets.
Quels sont les sujets traités dans les propositions ?
La première question de recherche était de savoir quelles étaient les thématiques évoquées dans les propositions formulées et votées par les participants à la consultation. Pour répondre à cette question, nous avons réalisé une analyse linguistique de type topic modeling (selon la méthode BERTopic) permettant d'extraire des sujets (thèmes) au sein d'un corpus de textes.
Une rédaction interactive et démonstrative du traitement est disponible en python dans un jupyter notebook.
La méthode Topic modeling
La base d'une analyse topic modeling consiste à transformer une chaîne de caractères en vecteur numérique, auquel on peut soumettre des algorithmes. Il existe différentes méthodes pour transformer ou "représenter" une phrase en vecteur : on peut découper la phrase et représenter chaque mot en nombres, ou on peut garder le contexte des mots en représentant chaque phrase en nombres. Cette dernière technique, dite de sentence embedding, est plus reconnue actuellement et est celle que nous avons préférée. Chaque phrase, quelle que soit sa longueur, se compose du même nombre de "dimensions" au travers desquelles se caractérisent les aspects uniques de la phrase. Les embeddings nous permettent de prendre en compte le contexte des mots employés dans une phrase.
Afin de créer les sentence embeddings, nous avons exploité un sentence transformer basé sur le modèle linguistique CamemBERT (principal modèle existant pour le français contemporain)1 et ajusté par la start-up française La Javaness. Cependant, pour s'adapter à toutes les nuances d'une phrase, le sentence embedding se définit par une multitude de dimensions, qui s’avèrent trop nombreuses pour qu'un algorithme puisse bien analyser la représentation. Nous avons donc appliqué la technique mathématique UMAP (Uniform Manifold Approximation and Projection for Dimension Reduction) recommandée par BERTopic afin de pouvoir regrouper les embeddings des phrases à l’aide de l'algorithme HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise).
La dernière étape de notre approche a consisté à donner un nom aux clusters de phrases créés par l'algorithme HBDSCAN. Pour créer les représentations des topics, nous avons utilisé un autre transformer : le c-TF-IDF (Class-based term frequency-inverse document frequency), qui se base sur le TfidfTransformer de scikit-learn. Pour terminer, nous avons relu les topics à la main, fusionné certains entre eux, puis donné à chacun un nom compréhensif.
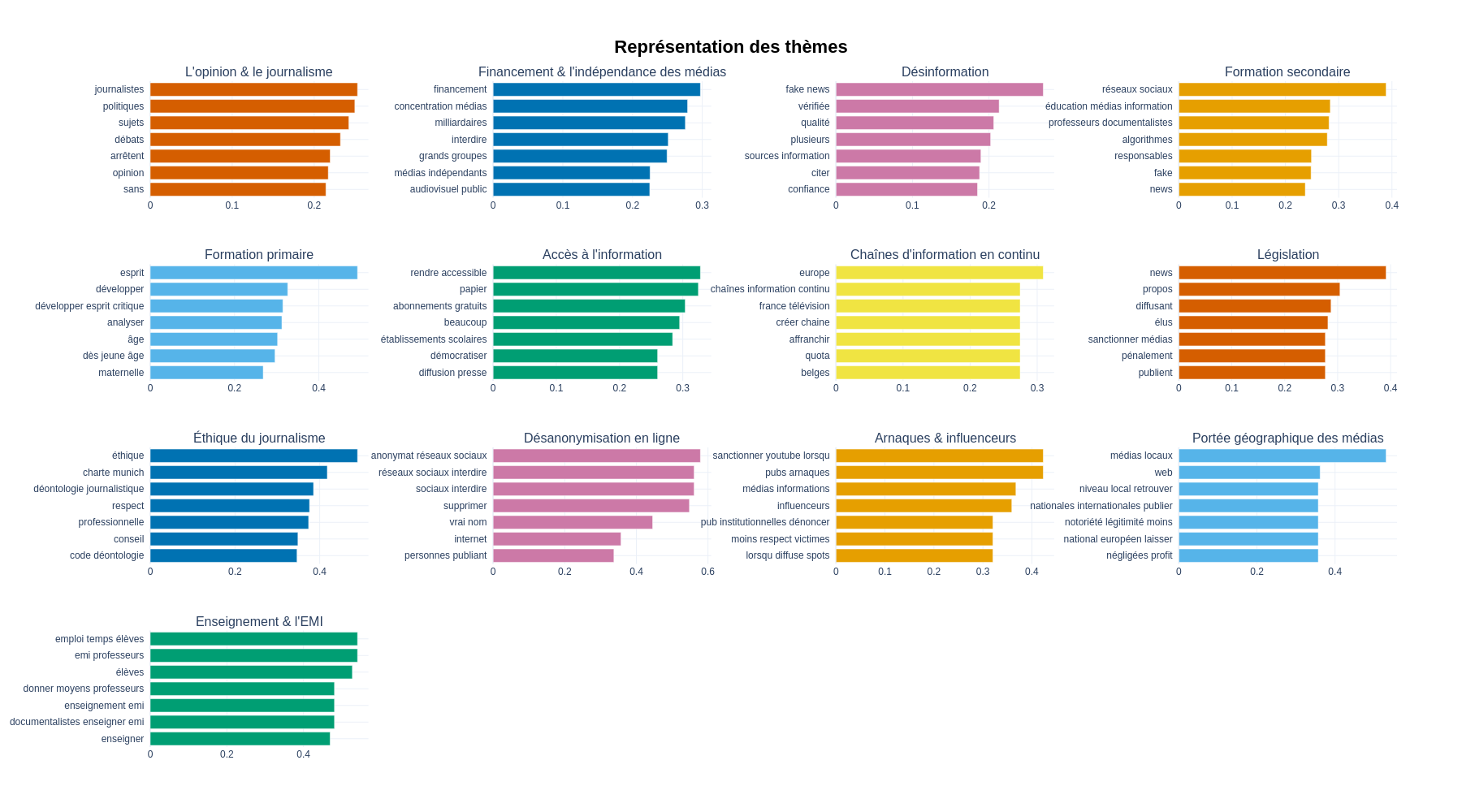
L'analyse du médialab a ainsi inféré 13 thèmes ressortant des 1 723 propositions valides de la consultation, 569 propositions ne se rattachant significativement à aucun des topics inférés.
La distribution des thèmes
Les algorithmes ont détecté et distingué trois thèmes liés à l'éducation :
- l'enseignement et l'EMI, (Éducation aux médias et à l'information) évoqué dans au moins 16 propositions,
- la formation primaire, concernant au moins 85 propositions,
- la formation secondaire traité dans au moins 152 propositions.
Si l'éducation est une préoccupation des participants lorsqu'ils sont interrogés sur "comment mieux s'informer", nous remarquons qu’ils sont significativement plus concernés par les habitudes et les compétences critiques des jeunes adolescents du secondaire - que par celles des autres tranches d’âge -, alors que ceux-ci n'étaient pas directement interrogés (l’âge moyen des participants est d'environ 50 ans).
Le regroupement des propositions qu'on a appelé « Formation secondaire » inclut des propositions qui ciblent explicitement l'éducation en secondaire et des propositions qui utilisent souvent les mots « fake » et « réseaux sociaux ». En comparaison, le regroupement qu'on a appelé « Formation primaire » est bien plus optimiste. Par rapport au thème de l'éducation dans le secondaire, qui parle des réseaux sociaux, des algorithmes et des fake news, le thème de l'éducation en primaire parle du développement, de l'âge et de de l'esprit, mais peu des outils numériques qui diffusent les fake news ni des fake news elles-mêmes. En d'autre termes, les deux thèmes inférés se distinguent d'un côté par un focus sur la diffusion de la désinformation envers les jeunes sur les réseaux sociaux, et de l'autre par le développement de l'esprit critique dès un jeune âge.
Compte tenu du déséquilibre entre les propositions concernant le secondaire et le primaire, il semble que les participants pensent bien plus fortement aux adolescents qu'aux enfants, lorsqu’ils envisagent la question de la désinformation en ligne.
D'un côté, ce biais pourrait révéler une idée reçue répandue chez les participants voulant que les adolescents sont, en général, plus connectés que les jeunes enfants et donc plus exposés à la désinformation. De l'autre, les participants ont pu être influencés par l’opinion selon laquelle les adolescents sont particulièrement touchés par la désinformation en ligne par rapport à la population en général. Si le premier lieu commun semble être correct, ce deuxième présupposé ne semble pourtant pas être bien justifié.
Chercheuse sur le projet De Facto et doctorante au médialab, Manon Berriche a mené une enquête dans un collège pour examiner comment les adolescents reçoivent des (fausses) informations et pourquoi ils décident ou non de les partager. Dans la lignée d’autres travaux, son enquête suggère que les adolescents partagent peu de fake news et sont moins enclins à la désinformation qu’à la non-information2. Plus encore, elle montre que les adolescents font preuve de discernement dans le choix des informations qu'ils partagent en fonction de la situation d’interaction dans laquelle ils se trouvent. Par exemple, plus un contexte est public ou régi par d’importantes contraintes énonciatives, plus les adolescents vont faire attention à la crédibilité des informations qu’ils partagent. À l’inverse, dans des contextes plus privés et relâchés, les adolescents ont plus tendance à mettre en circulation des fake news ou des rumeurs car celles-ci peuvent leur permettre de renforcer leur sociabilité.3
La proximité entre thèmes
Certains sujets évoqués dans les propositions sont liés ensemble, tels que ceux qui discutent de l'éducation des jeunes et de l'enseignement. Un regroupement hiérarchique (hierarchical clustering analysis ou HCA) montre la proximité entre les représentations en vecteur des topics inférés par les algorithmes. On a implémenté la méthode Ward pour relever la proximité entre topics4.
Comme attendu, le regroupement hiérarchique révèle une proximité entre les trois sujets qui appartiennent aux discussions de l'éducation : “Enseignement & EMI”, “Formation secondaire”, “Formation primaire”. De manière plus surprenante, on observe une proximité dans le regroupement hiérarchique entre les discussions sur les thèmes “Désinformation” et “L'opinion et le journalisme”. En outre, la discussion sur le thème “Législation” s'avère liée à deux sujets en particulier : d’une part, le regroupement hiérarchique trouve que la législation est liée aux soucis du thème “Arnaques & influenceurs” ; d’autre part, elle se lie aussi à la question de la “Désanonymisation en ligne”.
La similarité entre thèmes
La similarité cosinus est une autre méthode mathématique pour examiner les relations entre les représentations des thèmes inférés. Cette méthode prend les représentations de deux thèmes dans un espace vectoriel et détermine le cosinus de l'angle entre les deux vecteurs. En visualisant sur une matrice les similarités cosinus entre chaque paire de topic, de nouvelles relations ressortent.
Ainsi, le thème “Législation” s'avère par exemple lié plus particulièrement aux propositions relatives à l'éducation dans les écoles secondaires (“Formation secondaire”). Dans une moindre mesure, ce thème se montre également lié aux discussions sur la désinformation du thème “Accès à l'information”. Contrairement aux regroupements hiérarchiques, l'analyse par la similarité cosinus suggère que la similarité entre les trois thèmes sur l'éducation n'est pas si forte.
Quels sont les profils de vote sur les propositions ?
La seconde question de recherche s'appuie sur les votes reçus par les propositions. Les données brutes anonymisées partagées par Make.org se composent d'une part des métadonnées sur chaque proposition, et d'autre part d'une matrice des votes identiques sur les propositions. Cette dernière associe les propositions deux à deux en indiquant combien de paires de participants s'étant exprimé sur ces deux propositions ont voté selon chacune des neuf combinaisons possibles de votes pour, contre ou neutre.
Cette matrice se prête bien à l'analyse de réseau car on peut établir des liens entre les propositions de la consultation en fonction de leur co-soutien ou co-rejet par les participants. Pour réaliser cette analyse expérimentale, nous avons créé un réseau dans lequel les différentes propositions constituent les nœuds, reliés entre eux dès lors que des participants ont voté favorablement sur chacune des deux propositions. En reprenant l'exemple ci-dessus, les deux propositions présentées (sur l'école, et sur les chaînes d'information) sont deux nœuds liés entre eux puisque 27 participants les ont votées toutes les deux. Le nombre de participants ayant voté favorablement envers les deux propositions permet par ailleurs d'établir le poids de ce lien, lequel sera utilisé pour alimenter les algorithmes de spatialisation et clusterisation du réseau.
En menant cette analyse de réseau, nous cherchons à étudier si des familles de propositions votées favorablement par les mêmes participants émergent et, le cas échéant, si ces familles se recoupent avec les familles thématiques identifiées précédemment. On pourrait ainsi imaginer, par exemple, qu'un participant votant pour une proposition sur l'opinion et le journalisme voterait également en faveur d'une proposition sur l'éthique du journalisme. Les résultats de cette analyse expérimentale n'ont cependant pas confirmé cette hypothèse. Ils tendent au contraire plutôt à montrer que les clusters de participants ayant voté ensemble de mêmes propositions se répartissent de manière assez hétérogène à travers les différents sujets traités. Cependant, comme nous le verrons, il est fort probable que ces résultats soient faussés par la nature même des données et qu'ils ne reflètent en réalité que la méthodologie de soumission des propositions au vote des participants par la plateforme de Make.org.
Le script utilisé pour construire le réseau est disponible ici. Dans un premier temps, nous mettons en place les nœuds et les liens entre eux, dont le résultat est un graphe trop chargé puisque beaucoup de propositions ont reçu du co-soutien. Ensuite, nous avons réduit la complexité. L'objectif en réduisant la complexité est de révéler la colonne vertébrale du réseau, c’est-à-dire la structure relationnelle la plus fondamentale derrière tous les liens. Il existe plusieurs méthodes pour réduire la complexité d'un réseau. Nous avons préféré la méthode développée par M. Ángeles Serrano, Marián Boguña, et Alessandro Vespignani qui s'appelle le disparity filter (filtrage du réseau). Dans leur article, les chercheurs expliquent, "As a result, the disparity filter reduces the number of edges in the original network significantly, keeping, at the same time, almost all of the weight and a large fraction of nodes”5. Un outil que le médialab a développé, pelote, applique cette méthode. La méthode ne garde que les liens significatifs selon l’algorithme de filtrage du réseau. Le filtrage du réseau permet aux outils de visualisation de révéler ses clusters les plus évidents.
Recoupement de l'accord sur les propositions et des topics
En projetant les thèmes de la précédente analyse sur chaque proposition via des couleurs, on peut essayer ci-dessous d'identifier si les clusters formés par le co-soutien à des propositions se recoupent avec les sujets traités par chacune des propositions. Toutefois, l'hétérogénéité très forte des couleurs au sein des clusters du réseau semble indiquer très clairement que ce n'est pas le cas.
Il est cependant difficile de tirer une conclusion définitive car la méthodologie de la consultation influe très probablement fortement sur cette analyse de réseau. En effet, le fonctionnement de la plateforme Make.org vise à essayer autant que possible que l'ensemble des propositions soit évalué par un échantillon de participants de taille semblable. Ainsi, lorsqu'une nouvelle proposition est formulée par un participant, celle-ci n'a encore aucun vote et va être présentée prioritairement aux futurs participants afin d'équilibrer le nombre de votes entre les différentes propositions. En conséquence, les propositions ont tendance à être présentées aux utilisateurs par paquets chronologiques, ce qui influe logiquement sur l'analyse de réseau réalisée à partir de ces votes. Bien que ne disposant pas de la date à laquelle chaque proposition a été formulée, notre analyse de réseau risque en conséquence de refléter avant tout l'historique temporel des propositions formulées.
Recoupement de l'accord sur les propositions et de l'âge de leurs auteurs
Afin de mieux explorer cette seconde hypothèse, nous avons tenté d'examiner le même réseau au prisme de l'âge des auteurs de chaque proposition, projeté sous la forme d'un dégradé de couleur, allant du jaune pour les contributeurs les plus jeunes, au bleu pour ceux les plus âgés.
Alors que la projection des thèmes ne révélait aucune cohérence avec les clusters du réseau, cette nouvelle projection semble plus clairement indiquer des clusters majoritairement composés de propositions soumises par des personnes plutôt jeunes, et d'autres par des participants plus âgés. Vu au prisme de la méthodologie de consultation préalablement évoquée, cette projection semble pouvoir indiquer une participation à la consultation par vagues d'utilisateurs regroupés en générations, ce qui pourrait s'expliquer par la communication organisée autour de la consultation, ayant amené des groupes de lycéens et étudiants à contribuer à des périodes précises, tandis que les publics plus âgés par exemple lecteurs de la Presse Quotidienne Régionale auraient été concentrés à d'autres périodes en fonction de la mise en avant de la consultation sur les sites web de ces médias à ces périodes.
Conclusion
En conclusion, l'analyse de topic modeling a permis de compléter l'analyse réalisée par Make.org en identifiant automatiquement une quinzaine de sujets évoqués au travers de l'ensemble des 1 723 propositions valides de la consultation. La décomposition des sujets inférés suggère leur importance auprès des participants, telle que la prépondérance de l'école secondaire par rapport à la formation en primaire. Les sujets manifestement les plus importants pour les participants à la consultation autour de la question “comment permettre à chacun de mieux s'informer ?”, semblent concentrés autour de “L'opinion dans le journalisme”, le “Financement des médias”, la “Désinformation” et “L'éducation dans le secondaire”. L'analyse de la similarité entre les sujets révèle par ailleurs des liens importants entre plusieurs de ces thématiques. En revanche, l'analyse de réseau ne s'est pas révélée très concluante et semble surtout avoir reflété la méthodologie de consultation de la plateforme Make.org plutôt que les pratiques de vote des participants.
Pour prolonger ces travaux, une piste intéressante pourrait être d'enrichir les données sur les propositions avec les dates de soumission et de dernier vote par un participant de chaque proposition.
Notes :
1. Martin, L., Muller, B., Suárez, O., Javier, P., Dupont, Y. Romary, L. de la Clergerie, E., Seddah, D., Sagot, B. (2020). CamemBERT: a Tasty French Language Model. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.
2. Boyadjian, Julien (2020), « Désinformation, non-information ou sur-information ? Les logiquesd'exposition à l'actualité en milieux étudiants », Réseaux, n° 4, p. 21-52.
3. Berriche, M. (À paraître). La réception et le partage de (fausses) informations par les adolescents : des pratiques situées. Les enjeux de l'information ou de la communication.
4. Murtagh, Fionn, and Pierre Legendre. (2014). "Ward’s Hierarchical Agglomerative Clustering Method: Which Algorithms Implement Ward’s Criterion?" Journal of Classification.
5. Serrano, M. Ángeles, Marián Boguná, and Alessandro Vespignani. (2009). "Extracting the multiscale backbone of complex weighted networks." Proceedings of the national academy of sciences.
Lien vers la publication complète
Auteurs
Kelly Christensen, médialab